Производительность без цикла событий
Перевод статьи "Performance without the event loop"
Эта статья базируется на моей презентации, которую я представлял в этом году на конференции OSCON. Для краткости я немного переработал материал. Кроме того, я получил фитбек и в сявизи с этим добавил несколько моментов.
Основная тема всех разговоров про Go заключается в его крутости как языка для реализации серверов/сервисов: статические бинарники, мощная конкурентная обработка, высокая производительность.
В этой статье мы сосредоточимся на двух последних пунктах. Поговорим о том, как "прозрачность" языка и рантайма позволяют писать расширяемые сетевые сервисы и серверы без головной боли от блокирующего ввода/вывода и управления потоками.
Аргумент в пользу эффективности языка программирования
Прежде чем я перейду к техническим деталям, хотел бы описать несколько моментов, которые хорошо иллюстрируют какую нишу занимает Go.
Закон мура
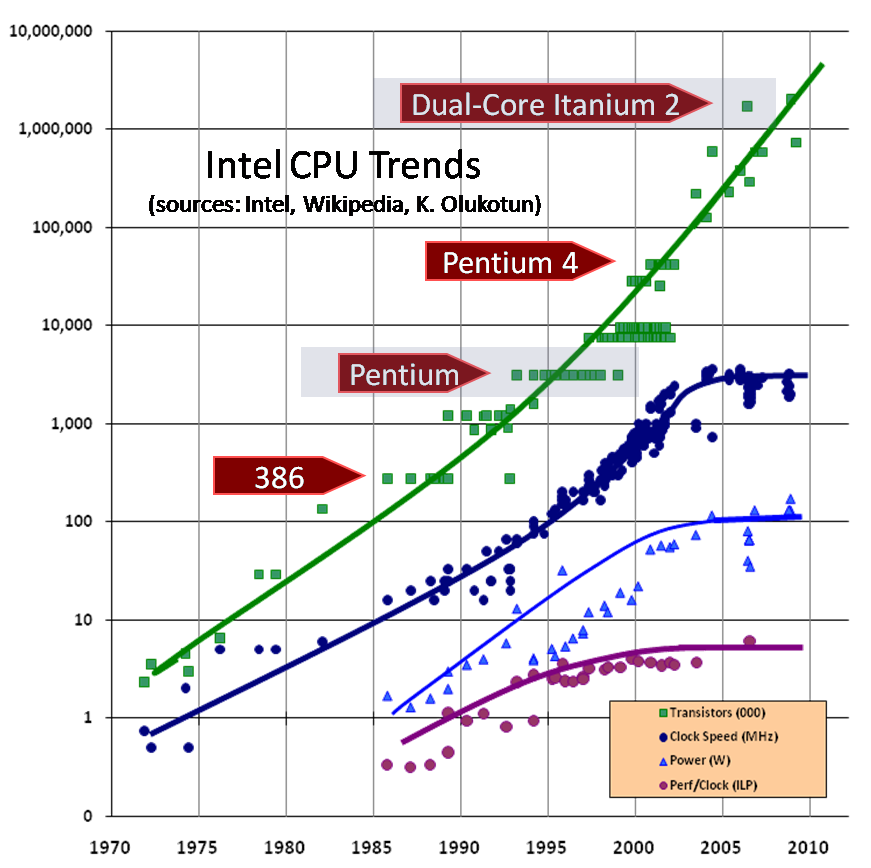
Очень часто закон Мура, который гласит, что число транзисторов на квадратный дюйм удваивается примерно каждые 18 месяцев, упоминается не совесм уместно.
Как вы знаете, тактовые частоты, которые являются функциями от совершенно разных свойств, достигли максимума десять лет назад во времена Pentium 4.
Переход от "экономии места" к "экономии энергии"

Sun Enterprise e450 — размер как у холодильника для бара и с таким же энерго потреблением.
Это Sun e450. На таких штуках мы работали, когда я начинал свою карьеру.
Эта вещь была очень массивной. Они устанавливались по три в стойку, которая была высотой в полметра, и каждый потреблял по 500 Вт.
За последние десять лет, датацентры перешли от экономии места к экономии энергии. В последних двух датацентрах, с которыми мне пришлось работать, мы вышли за ограничение по потреблению энергии, когда стойка была заполнена только на 1/3.
Размеры компьютеров стремительно уменьшались и теперь не так важно, сколько места занимает ваша машина в датацентре. В тоже время, теперь компьютеры потребляют в разы больше энергии, что делает проблематичным его охлаждение.
Причем, ограничения действуют и на макроуровне - вы не сможете получить мощности для 1200Вт 1RU серверов - и на микроуровне, так как всю эту энергию нужно как-то распределять по маленькому кусочку кремния.
Зачем столько энергии?

КМОП(CMOS) инвертор.
Это инвертор, один из простых логических элементов. Если на вход А поддать 1, то вход Q будет 0 и наоборот.
В наши дни все логические схемы создаются по технологии КМОП(комплементарная структура металл-оксид-полупроводник; англ. CMOS, complementary metal-oxide-semiconductor). Ключевое тут "комплементарная". Каждый логический элемент внутри процессора реализован с помощью пары транзисторов, реализующих переключение в 0 и 1.
Независимо от того, замкнут элемент или нет(0 или 1), ток не течет напрямую от источника к потребителю. Но существует очень кратковременное состояние, когда оба транзистора замкнуты и проводят так называемый ток утечки.
Потребляемая мощность и тепловыделение прямо пропорциональна количеству переключений в секунду(тактовая частота процессора).
Стремление уменьшить размеров процессора привело к необходимости задуматься над потреблением энергии. Причем, мы говорим не только о "зеленой" экономии. В первую очередь, важно держать под контролем тепловыделение и энергопотребление для того, чтобы микропроцессор мог нормально работать и не разваливаться.
С учетом, что тактовые частоты уменьшаются а энергопотребление увеличивается, то повышение производительности может быть только благодаря твикам микроархитектуры и эзотерическим векторным инструкциям, что, прямо скажем, не очень полезно для общих вычислений. В сумме, каждое новое поколение микроахитектур дает прирост максимум в 10% (5-ти летний цикл), а последнее время и того меньше - всего 4-6%.
"Бесплатных обедов больше не будет"("The free lunch is over")
Теперь ясно, что "железо"" не становится быстрее. Если вы когда ни будь сталкивались с проблемой производительности и масштабируемости, то вы согласитесь со мной, что дни, когда можно было просто добавить больше оборудования, уже прошли, по крайней мере в том виде как это было раньше. Как сказал Герб Саттер "Бесплатных обедов больше не будет".
Теперь вам нужен эффективный язык, так как неэффективные языки не оправдают себя в производственных масштабах.
Аргумент в пользу конкурентных языков
Мой второй аргумент - это следствие из первого. Процессоры не станут быстрее, но они будут "шире". Что очевидно, туда же напихивают кучу всего.

Эмуляция мультредового режима(или Hyper Threading, как любят называть это в Intel) позволяет одноядерному процессору работать с несколькими потоками и для этого нужно сравнительно немного дополнительного оборудования. Intell использует Hyper Threading, чтобы занять сегмент рынка. Oracle и Fujitsu значительно агрессивней проталкивают эту технологию, в их процессорах используется от 8 до 16 аппаратных потоков на ядро.
Двухъядерные процессоры стали реальностью после приходя в конце 1990 Pentium Pro и в настоящее время большинство серверов работают именно на многоядерной архитектуре. Увеличение числа транзисторов позволило разместить процессор вместе с его братьями на одном чипе. Двухядерные процессоры на носимых компьютерах, четырехъядерные на десктопах, много-многоядерные процессоры на серверах - теперь это все реальность. Вы можете купить процессор с таким количеством ядер, на сколько вам хватит денег.
А вот чтобы воспользоваться преимуществами многоядерной архитектуры, вам нужен язык с действительно хорошей реализацией конкурентности.
Процессы, треды и go-рутины
В Go есть go-рутины, которые являются основой его конкурентности. Сейчас я вернусь немного в прошлое, чтобы рассказать историю, которая привела к созданию go-рутин.
Процессы
В прошлом, компьютеры выполняли только одну задачу в один момент времени в рамках пакетной обработки. В 60-е годы необходимость более интерактивных форм расчетов приводит к созданию мультипроцессорных операционных систем или систем с разделением по времени. Этот подход успешно использовался в 70-е для различных сетевых сервисов, ftp, telnet, rlogin и более позднего CERN httpd(разработан Tim Burners-Lee). Основная идея заключается в форке и создании нового процесса для каждого нового сетевого соединения.
В системах разделения времени создается иллюзия параллельной обработки благодаря быстрому переключению процессора между различными активными процессами, сохраняя состояние текущего процесса и восстанавливая следующий процесс перед продолжением обработки. Это называется переключением контекста.
Переключение контекста

При переключении контекста есть три затратных момента.
- Ядро должно записывать содержимое всех регистров процессора для конкретного процесса и восстанавливать эти значения для другого процесса. Так как переключение процессов может произойти в любой момент исполнения, то операционная систем должна хранить содержимое всех этих регистров, так как она точно не знает, какой из процессов исполняется в это момент.
- Ядро должно флушить виртуальные адреса процессора для мапинга на физические адреса(TLB кеш).
- Накладные расходы операционной системы на переключение процессов и накладные расходы на планирование и выбор следующего процесса для исполнения.
Эти расходы фиксированы относительно аппаратного оборудования и зависят от количества работы проделанной между переключениями, что позволяет амортизировать расходы на переключение - чем чаще переключения, тем меньше работы будет сделано в результате.
Треды
В результате были придуманы треды, которые концептуально очень похожи на процессы, но могут работать с одной и той же областью памяти. Так как треды пользуются одними и тем же адресным пространством, то ими проще управлять, они лучше поддаются планированию, их быстрее создавать и быстрее переключаться между ними.
Треды все еще требуют некоторых затрат на переключение, все еще есть необходимость сохранять множество состояний. По сути, go-рутины это шаг в будущее тредов.
Go-рутины
Вместо того, чтобы полагаться на процессорное разделение времени, go-рутину планируются кооперативно. Переключение go-рутин происходит только в четко определенных точках, в момент явного вызова планировщика Go. Основные точки, в которых go-рутины заставляют сработать планировщик:
- Отправка и прием сообщений через каналы, в случае если эти операции будут блокироваться.
- Использование оператора
go, с помощью которого инициализируется новая go-рутина. Хотят нет никакой гарантии, что новая рутина запустится сразу же. - Блокирующие системные вызовы, такие как обращение к файлам или хождения в сеть.
- Остановка для работы сборщика мусора.
Все это места, в которых конкретная go-рутина не может продолжить работу, пока у нее не будет больше данных или ресурсов.
Go рантайм запускает множество go-рутин в рамках одного треда. Это делает go-рутины такими дешевыми в плане создания и переключения между ними. Десятки тысяч go-рутин в одном процессе - это нормально, сотни тысяч - тоже не проблема.
С точки зрения языка, планирование выглядит как вызов функции и имеет аналогичную семантику. Компилятор знает какие регистры используются и сохраняет их значения автоматически. Поток обращений в планировщик закреплен за стеком go-рутины, но может быть возвращен с другим стеком. Это довольно сильно отличается от потоковых приложений, в которых поток может быть вытеснен в любое время при выполнении любой инструкции.
Такой подход обеспечивает относительно небольшое количество системных потоков для Go процесса, с учетом, что рантайм старается приатачить запущенную go-рутину к более "свободному" системному потоку.
Управление стеком
В предыдущем разделе я рассказал как go-рутины позволяют уменьшит накладные расходы при управлении большим количеством (иногда сотни тысяч) параллельных потоков. У подхода с использованием go-рутин есть еще одна положительная сторона - это управление стеком.
Адресное пространство процесса
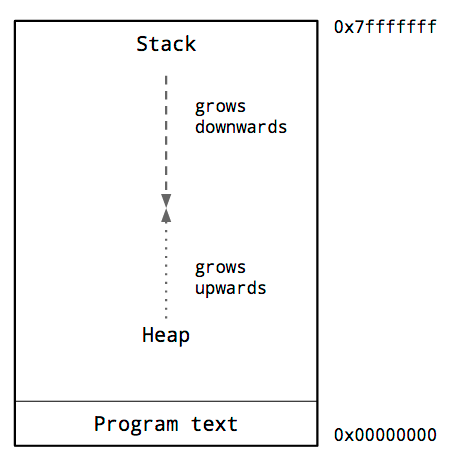
Эта диаграмма показывает типичное использование памяти процессом. Ключевое, что нас тут интересует - это расположение стека(stack) и кучи(heap).
Традиционно, куча располагается в нижнем адресном пространстве, но выше самой программы и растет вверх.
Стек расположен вверху адресного пространства виртуальной памяти и растет в низ.
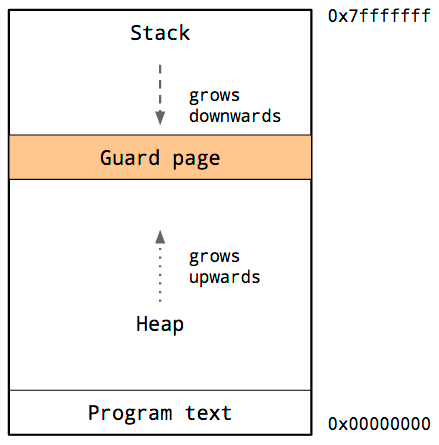
Так-как перезапись стека данными из кучи(или наоборот) приведут к катастрофе, операционная система организует некоторую недоступную память между стеком и кучей.
Это называется защитной страницей(guard page), что эффективно ограничивает размер стека процесса, как правило, в размере нескольких мегабайт.
Стек потока
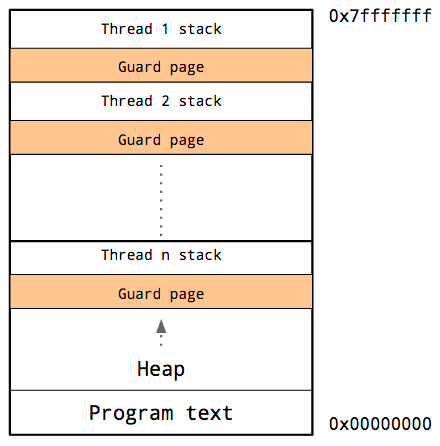
Потоки имеют общее адресное пространство, таким образом, для каждого треда нужно собственный стек и свою собственную защитную страницу.
Так как у нас нет возможности предсказать размер стека, то нужно зарезервировать много памяти для стека каждого потока. Нам остается надеяться, что размера стека хватит и мы не наткнемся на защитную страницу.
Недостаток в том, что при увеличении количества потоков, размер свободного адресного пространства уменьшается.
Управление стеком в Go-рутинах
Раньше программист мог рассматривать стек и кучу как достаточно большие, по сравнению с объемом всей памяти. Однако, недостатком была довольно сложная модель самого процесса.
Потоки немного исправили ситуацию в лучшую сторону, но теперь приходится заботиться о размере стека, иначе вы либо выйдете за пределы адресного пространства, либо за пределы стека.
Мы знаем, что множество go-рутин могут выполнятся в рамках небольшого количества потоков. Но как обстоят дела со стеками для этих go-рутин?
Размеры стека для go-рутин
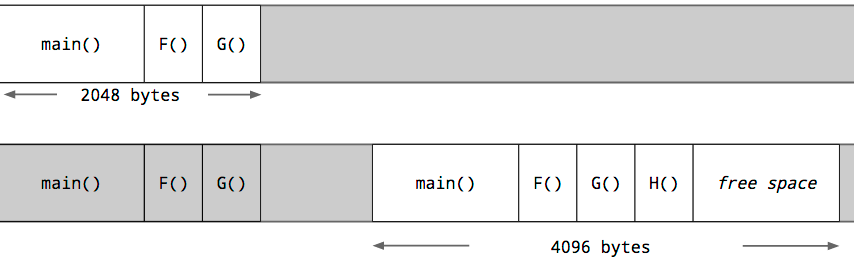
Каждая go-рутина стартует с маленьким стеком, аллоцированным из кучи. Размер этого стека не постоянный, но в Go 1.5 go-рутина стартует со стеком в 2k аллокаций.
Вместо использования защитной страницы, компилятор Go выполняет проверку размера стека при каждом вызове функции. Если места хватает, то функция работает в обычном режиме.
Если места недостаточно, рантайм выделяет больший кусок на куче под стек, копирует содержимое текущего стека в новый, очищает старый и перезапускает вызов функции.
Благодаря такому подходу go-рутины намного дешевле потоков. Кроме того, стек go-рутины может сокращаться во время сборки мусора, если большая часть стека не используется.
Встроенный сетевой опрашиватель(poller)
В 2002 Дэн Кегель опубликовал свое исследование под названием "Проблема 10000 соединений". Суть этого исследования в том, что для написания софта, который сможет обрабатывать 10000 TCP сессий, нужны определенные подходы. Здравый смысл подсказал использовать потоки, а позже - цикл событий(event loop).
Потоки все еще создают некоторый оверхед, особенно с точки зрения планирования памяти. Модель событийного цикла избавляет от этих накладных расходов, но она привод к необходимости писать код в особом стиле с использованием обратных вызовов.
Go предоставляет программистам лучшее из обеих подходов.
Решение "Проблемы 10000 соединений" в Go стиле.
Как правило, системные вызовы в Go это блокирующие операции, в том числе чтение и запись по дискриптору файла. Планировщик Go разпуливает эту ситуацию путем нахождения свободного потока или свопинга другого потока для продолжения работы go-рутин, пока оригинальный поток заблокирован. На практике это хорошо работает при небольшом количестве операций ввода/вывода, так как можно очень быстро исчерпать лимиты по количеству открытых файлов и операциям ввода/вывода.
Однако, во время работы с сетью, при таком дизайне, в каждый момент времени большинство ваших go-рутин будут заблокированы в ожидании ввода/вывода. Вам нужно будет запустить почти столько же потоков, сколько go-рутин простаивают в ожидании трафика. К счастью, в Go реализован опрашиватель для сетевых обработчиков, который работает очень эффективно, благодаря интеграции пакетов для работы с сетью и рантайма.
В старых версиях Go роль сетевого опрашивателя играла одна единственная go-рутина, которая была ответственна за опрос для уведомлений о готовности и работала с использованием kqueue или epoll. Опрашивающая go-рутина посылала сообщения заблокированной рутине через канал. Это означает, что планировщик ничего не знал о источнике или необходимости переключения("пробуждения").
В текущей версии Go опрашиватель интегрирован в сам рантайм. Соответственно, рантайм знает какая go-рутина ждет сокет и может вернуть go-рутину на том же процессоре как только придет пакет. Таким образом, неплохо увеличивается пропускная способность.
Go-рутины, управление стеком и интегрированный сетевой опрашиватель
Go-рутины обеспечивают мощную абстракцию, которая позволяет программисту меньше беспокоится о различных пулах и циклах событий.
Стек у go-рутин достаточно большой и нет необходимости заботится о стеке потока или пуле потоков.
Интегрированный сетевой опрашиватель позволят избежать кода в стиле обратных вызовов в тоже время предоставляя эффективный ввод/вывод поверх операционной системы.
Райнтайм всегда в курсе того сколько потоков необходимо для обслуживания ваших go-рутин и не даст простаивать ядрам процессора.
Все эти фичи вполне прозрачны для программиста.