{kind=link}
Пишем простой балансировщик нагрузки на Go

Перевод Let’s Create a Simple Load Balancer With Go.
Балансировщик нагрузки играет ключевую роль в веб-архитектуре. Он позволяет распределить нагрузку между несколькими бекендами. Это дает возможность масштабировать сервисы и делать их более устойчивыми к сбоям - если упадет один бекенд, то балансировщик будет слать запросы к другому.
После экспериментов с серьезными балансировщиками, такими как NGINX, я решил для фана написать свой. Реализовывать я его я буду на Go. Golang - современный язык с первоклассной поддержкой конкурентности. У него богатая стандартная библиотека, которая позволяет реализовать производительные приложения в несколько строк кода. И все это линкуется в статический бинарник для простой поставки.
Как работает наш простой балансировщик
Для балансировки нагрузки используются несколько разных стратегий. Например:
- Раунд Робин - Нагрузка распределяется равномерно. Предполагается, что все бекенды могут обрабатывать одинаковое число запросов
- Взвешенный Раунд Робин - Веса указываются с учетом вычислительной мощности бекендов.
- По меньшему количеству соединений - Запрос уходит на тот сервер, к которому сейчас меньше всего подключений
Для нашего простого балансировщика реализуем самый простой алгоритм - Раунд Робин
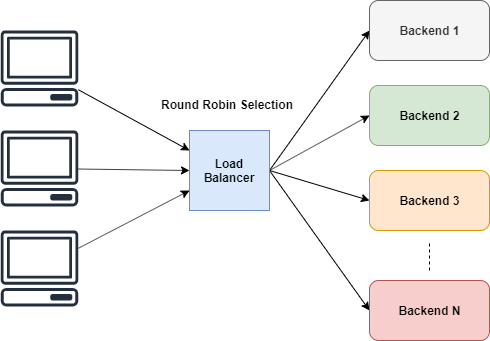
Выбор в Раунд Робин алгоритме
Этот алгоритм простой по определению. Воркеры(или бекенды) обрабатывают запросы по очереди.
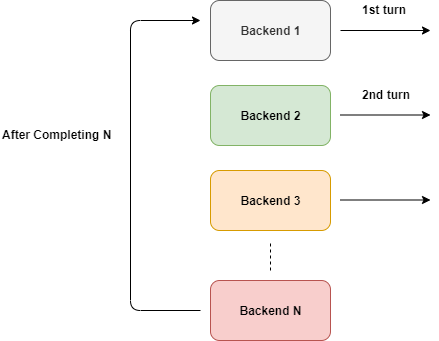
Как видно из схемы, выбор бекенда происходит по кругу. Но мы не можем использовать такой подход в лоб.
Что будет если отвалится один из бекендов? Нам не нужно отправлять трафик на нерабочий сервер. Нам придется добавить условие чтобы все запросы уходили только на живые бекенды.
Начнем с определения структур
Мы определились с планом и знаем что нам нужно хранить информацию по нашим бекендам. Нужно отслеживать состояние бекенда(жив они или мертв) и знать его URL.
Структура для будет выглядеть так:
type Backend struct {
URL *url.URL
Alive bool
mux sync.RWMutex
ReverseProxy *httputil.ReverseProxy
}
Чуть позже я расскажу о остальных полях в структуре Backend.
Теперь нам нужно собрать несколько бекендов вместе. Нам нужен слайс и счетчик. Все это будет хранится в отдельной структуре ServerPool.
type ServerPool struct {
backends []*Backend
current uint64
}
Используем обратный прокси
Цель балансировщика - маршрутизация трафика на различные бекенды и возврат результата клиенту.
Согласно документации из стандартной библиотеки Go
Обратный прокси - это HTTP обработчик, который получает входящий запрос и передает его на другой сервер, проксируя ответ обратно клиенту
И это именно то что нам нужно. Не стоит снова изобретать колесо. Будем пропускать все наши запросы через ReverseProxy.
u, _ := url.Parse("http://localhost:8080")
rp := httputil.NewSingleHostReverseProxy(u)
// initialize your server and add this as handler
http.HandlerFunc(rp.ServeHTTP)
Вызов httputil.NewSingleHostReverseProxy(url) инициализирует экземпляр обратного прокси который будет пересылать все запросы на указанный url. В этом примере все запросы передаются на localhost:8080, а ответы отправляются обратно клиенту.
Если взглянем на сигнатуру метода rp.ServeHTTP, то увидим что она соответствует сигнатуре HTTP обработчика и этот метод можно передавать в http.HandlerFunc.
Больше примеров работы с обратным прокси в документации.
Для нашего балансировщика создадим экземпляр ReverseProxy для каждого URL в структуре Backend И каждый обратный прокси будет перенаправлять запросы на этот URL.
Процесс выбора
Для правильного выбора следующего бекенда нужно научится пропускать мертвые. Но для начала будем все считать.
Клиенты будут подключаться к балансировщику одновременно и каждый из них будет запрашивать следующий узел(бекенд). Это приведет к гонкам. Для предотвращения гонок можно воспользоваться мьютексом. Но это лишнее - нам не нужно блокировать ServerPool, нужно только увеличивать счетчик на 1.
Идеальное решение - атомарное инкрементирование. И Go поддерживает его в пакете atomic.
func (s *ServerPool) NextIndex() int {
return int(atomic.AddUint64(&s.current, uint64(1)) % uint64(len(s.backends)))
}
Тут мы атомарно увеличиваем значение на единицу и возвращаем модуль по количеству наших бекендов. Это и будет индекс следующего узла.
Выбор только живых бекендов
Теперь мы можем легко получать индекс следующего узла. Нам осталось научится пропускать мертвые бекенды и почти все готово.
GetNext() - всегда возвращает значение между 0 и длиной слайса. В любом случае мы получаем индекс следующего узла и если он мертвый, то ищем первый подходящий узел по всему слайсу.
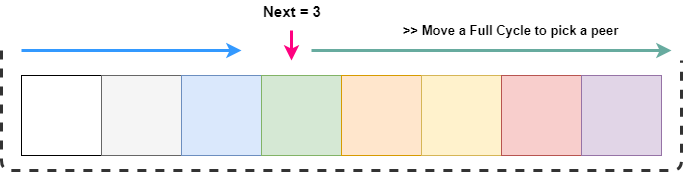
Как видно на картинке, мы хотим пройти по всему слайсу с позиции next. Это можно сделать пройдя next + длина слайса операций. Но индексы нашего слайса должны быть в пределах от 0 до длины всего слайса. Это можно провернуть используя модуль по длине слайса как делали это раньше.
Как только находим подходящий узел - делаем его текущи инкрементируя счетчик
Выглядит все это так:
// GetNextPeer returns next active peer to take a connection
func (s *ServerPool) GetNextPeer() *Backend {
// loop entire backends to find out an Alive backend
next := s.NextIndex()
l := len(s.backends) + next // start from next and move a full cycle
for i := next; i < l; i++ {
idx := i % len(s.backends) // take an index by modding with length
// if we have an alive backend, use it and store if its not the original one
if s.backends[idx].IsAlive() {
if i != next {
atomic.StoreUint64(&s.current, uint64(idx)) // mark the current one
}
return s.backends[idx]
}
}
return nil
}
Избавляемся от гонок в структуре Backend
У нас есть серьезная проблема - в структуре Backend есть поля которые могут изменяться или читаться из разных горутин одновременно.
И нам известно, что эти поля будут больше читаться чем записываться. Поэтому стоит использовать RWMutex чтобы сериализовать доступ с полу Alive.
// SetAlive for this backend
func (b *Backend) SetAlive(alive bool) {
b.mux.Lock()
b.Alive = alive
b.mux.Unlock()
}
// IsAlive returns true when backend is alive
func (b *Backend) IsAlive() (alive bool) {
b.mux.RLock()
alive = b.Alive
b.mux.RUnlock()
return
}
Обработка запросов к балансировщику
Чтобы все заработало, нам нужно реализовать простой метод обработки входящих запросов. Он будет фейлиться если все бекенды недоступны.
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
Этот метод можно передавать в HandlerFunc для HTTP сервера
server := http.Server{
Addr: fmt.Sprintf(":%d", port),
Handler: http.HandlerFunc(lb),
}
Отправляем трафик только на живые бекенды
В реализации выше есть серьезная проблема - мы не знаем в каком состоянии бекенд после вызова serverPool.GetNextPeer(). Чтобы это понять нужно проверить жив ли наш узел.
У нас есть два пути реализации проверки состояния:
- Активная проверка - перед каждым запросом проверяем состояние бекенда и если он умер, то пропускаем его.
- Пассивная проверка - периодически через фиксированный интервал времени проверяем состояние всех бекендов
Активная проверка работоспособности бекендов
ReverseProxy вызывает колбек функцию ErrorHandler в случае ошибки. Можно ее использовать для определения состояния узла. Ниже реализация:
proxy.ErrorHandler = func(writer http.ResponseWriter, request *http.Request, e error) {
log.Printf("[%s] %s\n", serverUrl.Host, e.Error())
retries := GetRetryFromContext(request)
if retries < 3 {
select {
case <-time.After(10 * time.Millisecond):
ctx := context.WithValue(request.Context(), Retry, retries+1)
proxy.ServeHTTP(writer, request.WithContext(ctx))
}
return
}
// after 3 retries, mark this backend as down
serverPool.MarkBackendStatus(serverUrl, false)
// if the same request routing for few attempts with different backends, increase the count
attempts := GetAttemptsFromContext(request)
log.Printf("%s(%s) Attempting retry %d\n", request.RemoteAddr, request.URL.Path, attempts)
ctx := context.WithValue(request.Context(), Attempts, attempts+1)
lb(writer, request.WithContext(ctx))
}
В этом коде мы используем силу замыканий для обработки ошибок. Мы захватываем URL адрес сервера в наш метод. В обработчике мы проверяем количество повторов и если их меньше 3, то заново посылаем тот же запрос на тот же сервер и увеличиваем счетчик повторов. Ошибка может возникнуть временно(например у сервера закончились сокеты для обработки такого количества клиентов) и в этом случае не нужно помечать сервер как мертвый. Сервер может стать доступен через небольшой промежуток времени, поэтому мы используем таймер и откладываем следующий повтор примерно на 10 миллисекунд.
После провала всех повторов этот бекенд помечается как мертвый.
Дальше мы отправляем этот же запрос на другой сервер. Количество попыток подсчитываем используя пакет context. После инкремента номера попытки мы заново вызываем lb для выбора нового бекенда и передаем туда контекст.
В самой функции lb нам обязательно нужно проверять сколько попыток уже прошло до обработки самого запроса. Если попыток больше чем нужно, то прерываем запрос.
Реализация будет рекурсивной:
// lb load balances the incoming request
func lb(w http.ResponseWriter, r *http.Request) {
attempts := GetAttemptsFromContext(r)
if attempts > 3 {
log.Printf("%s(%s) Max attempts reached, terminating\n", r.RemoteAddr, r.URL.Path)
http.Error(w, "Service not available", http.StatusServiceUnavailable)
return
}
peer := serverPool.GetNextPeer()
if peer != nil {
peer.ReverseProxy.ServeHTTP(w, r)
return
}
http.Error(w, "Service not available", http.StatusServiceUnavailable)
}
Использование контекста
Пакет context позволяет сохранять данные на момент запроса. Мы используем эту возможность для подсчета количества попыток и повторений.
Сначала нужно определить ключи для контекста. Рекомендуется использовать не пересекающиеся интовые ключи вместо строк. В Go есть ключевое слово для пошаговой инициализации констант, каждая из которых содержит уникальное значение. Это идеальное решения для ключей контекста.
const (
Attempts int = iota
Retry
)
Теперь можно получать значения из контекста почти как из хешмапы. Дефолтное значение задаем сами в зависимости от необходимости.
// GetAttemptsFromContext returns the attempts for request
func GetRetryFromContext(r *http.Request) int {
if retry, ok := r.Context().Value(Retry).(int); ok {
return retry
}
return 0
}
Пассивная проверка работоспособности
Пассивная проверка позволяет возвращать мертвые бекенды если они ожили или выявлять их независимо от запросов. Для этого мы пингуем бекенды через определенный интервал времени и проверяем их статусы.
В нашей реализации мы пытаемся установить TCP соединение. Если это удалось - бекенд считается живым. Эту логику можно поменять на вызов определенного ендпоинта, например /status. Важно не забывать закрывать соединение чтобы уменьшить нагрузку на сервер - иначе у сервера закончатся ресурсы.
// isAlive checks whether a backend is Alive by establishing a TCP connection
func isBackendAlive(u *url.URL) bool {
timeout := 2 * time.Second
conn, err := net.DialTimeout("tcp", u.Host, timeout)
if err != nil {
log.Println("Site unreachable, error: ", err)
return false
}
_ = conn.Close() // close it, we dont need to maintain this connection
return true
}
Теперь проходим по всем бекендам и определяем их статус
// HealthCheck pings the backends and update the status
func (s *ServerPool) HealthCheck() {
for _, b := range s.backends {
status := "up"
alive := isBackendAlive(b.URL)
b.SetAlive(alive)
if !alive {
status = "down"
}
log.Printf("%s [%s]\n", b.URL, status)
}
}
Запускаем эту проверку периодически с использованием таймера
// healthCheck runs a routine for check status of the backends every 2 mins
func healthCheck() {
t := time.NewTicker(time.Second * 20)
for {
select {
case <-t.C:
log.Println("Starting health check...")
serverPool.HealthCheck()
log.Println("Health check completed")
}
}
}
Вызов <-t.C возвращает значение каждые 20 секунд. select позволяет отловить эти события - он блокируется пока в канале не появится новый элемент.
Запускаем весь этот код в отдельной горутине
go healthCheck()
Заключение
Мы обсудили много разных тем в этой статье
- Выбор по Раун робину
- Обратный прокси из стандартной бибилотеки
- Мьютексы
- Атомарные операции
- Замыкания
- Обратные вызовы
- Конструкция
select
Есть еще много способов улучшения для нашего игрушечного балансировщика.
Например:
- Использовать кучу для ускорения поиска живых бекендов
- Собирать статистику
- Реализовать другие методы балансировки
- Добавить конфигурационный файл
- и так далее
Весь исходный код есть на github.
Спасибо за внимание :)