{kind=link}
Глубинное обучение с нуля в Go - Часть 1: графы
Перевод статьи “Deep Learning from Scratch in Go - Part 1: Equations Are Graphs”

Это первая статья из целого цикла про алгоритмы глубинного обучение. Я постараюсь начать с самых азов и постепенно двигаться к объяснению современных разработкам в этой области.
Глубинное обучение, на самом деле, совсем не новомодное изобретение. Сама идея появилась еще в начале 1980х. Но в наше время компьютеры стали значительно мощнее. В этой статье мы начнем разбираться с этой темой, начиная со знакомых вещей, со временем вникая в принципы работы глубинного обучения. Мы не будем нырять с головой в глубинное обучение на протяжении нескольких первых статей и вам не придется столкнутся с кучей непонятных терминов в самом начале, все произойдет постепенно.
И начнем мы с изучения понятий необходимых для старта. В этом цикле мы не раз будем сталкиваться с понятием “граф”, которое относится, как можно догадаться, к [теории графов](https://en.wikipedia.org/wiki/Graph_(discrete_mathematics). Не путайте с “графиком”.
Вычисления
Начнем утверждения утверждение: любую программу можно представить как граф. Конечно же, это не супер новое открытие. Но, на самом деле, оно имеет революционное значение. Это фундаментальное утверждение, на котором базируются большинство современных достижений в компьютерных науках. Конечно, вы можете не знать всей необходимой теории, нужно прояснить несколько моментов:
- Все современные компьютерные программы запускаются на, так называемой, Машине Тьюринга.
- Любая машина Тьюринга эквивалентна нетипизированному лямбда вычислению (стоит почитать про тезис Чёрча-Тьюринга).
- Лямбда вычисления можно представить в виде графа.
- Соответственно любую программу можно представить в виде графа.
Для большей конкретики давайте рассмотрим простой пример:
1func main() {
2 fmt.Printf("%v", 1+1)
3}
Эта программа может быть представлена в виде абстрактного синтаксического дерева(AST), вроде такого (для построения AST использовалась библиотека, работающая поверх goast-viewer):
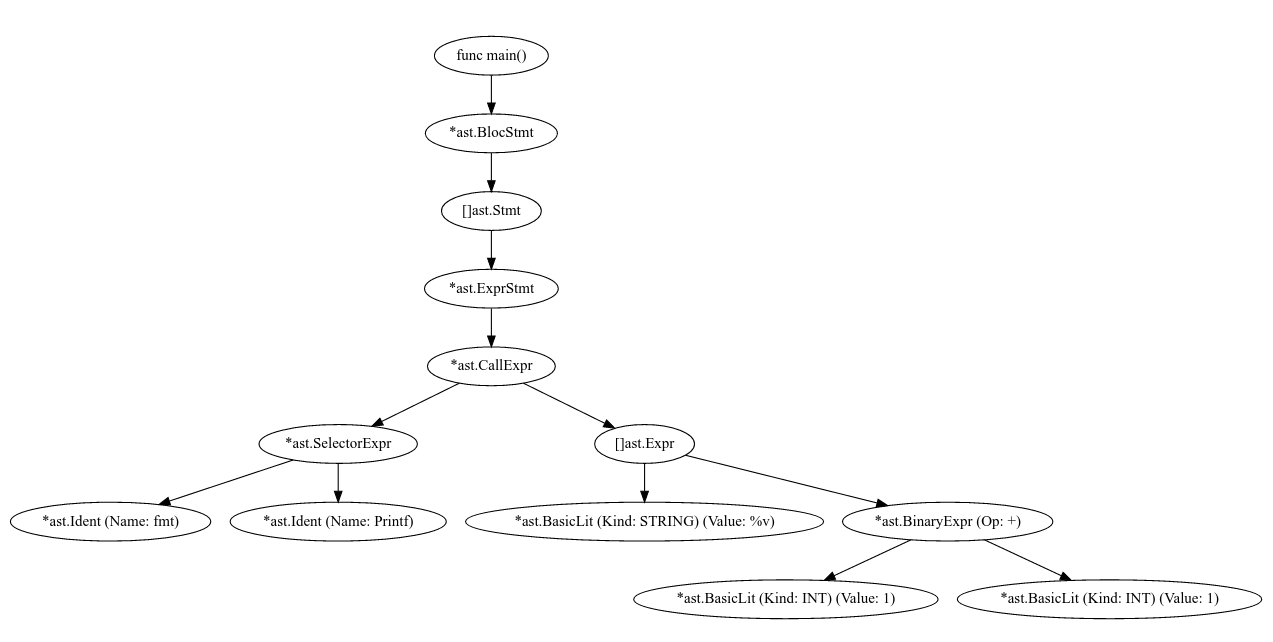
Глядя на этот пример, можно догадаться, что все уравнения могут быть представлены в виде компьютерной программы, а компьютерная программа может быть представлена в виде графа. Давайте рассмотрим поближе выражение 1+1:
Это выражение можно представить в виде упрощенного графа, откуда мы удалили все не нужное:
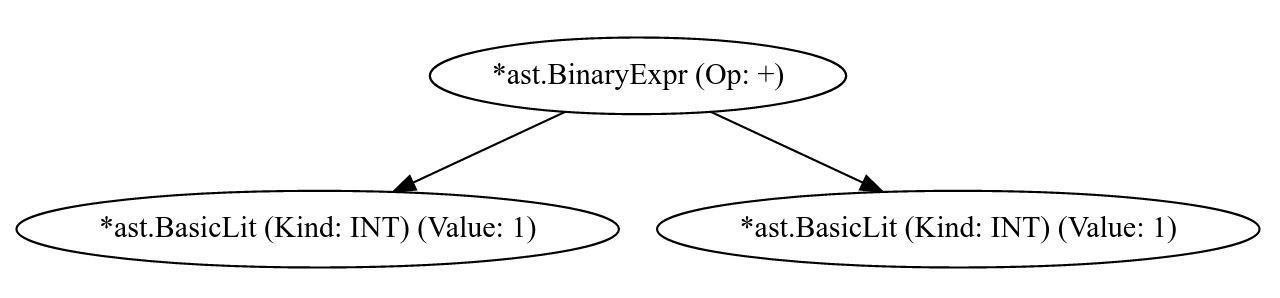
Как видно, граф расширяется в глубину, начиная с вершины. Вычисляемые значения в программе как бы всплывают наверх. Когда программа запускается, она начинает выполнятся с самого верха. Но нода не может быть вычислена пока не будут вычислены все зависимости. Стрелки показывают на зависимости между нодами. К примеру, значение ноды *ast.BinaryExpr зависит от значений *ast.BasicLit (тип: INT). Как только мы поняли что оба значения 1 и знаем что делает +, то модем вычислить значение ноды *ast.BinaryExpr которое будет равно 2.
Уравнения в виде графов
Почему мы потратили столько времени чтобы представить 1+1 в виде графа? Потому что этот подходя является основой всего глубинное обучение, только вместо 1+1 будут более сложные уравнения. Не пугайтесь слова “уравнения”, все не так страшно. Лично я один из тех людей, кто занимается глубинным обучением (и другими областями машинного обучения) без каких либо обширных математических познаний. По моему опыту, нет более надежного способа обучения, чем визуализация рассматриваемых концепций.
Большинство популярных библиотек для глубинного обучения, такие как Tensorflow, Theano или моя собственная Go библиотека Gorgonia, используют концепцию представления уравнений в виде графа. Что еще более важно, все эти библиотеки дают доступ к этому графу, для его модификации из программы.
Таким образом, мы можем создать что-то вроде такого:
func main() {
// Создаем граф.
g := G.NewGraph()
// Создаем ноду "x" со значением 1.
x := G.NodeFromAny(g, 1, G.WithName("x"))
// Создаем ноду "y" со значением 1.
y := G.NodeFromAny(g, 1, G.WithName("y"))
// z := x + y
z := G.Must(G.Add(x, y))
// Создаем виртуальную машину для вычисления графа.
vm := G.NewTapeMachine(g)
// Запускаем виртуальную машину.
vm.RunAll()
// Выводим знаяение z.
fmt.Printf("%v", z.Value())
}
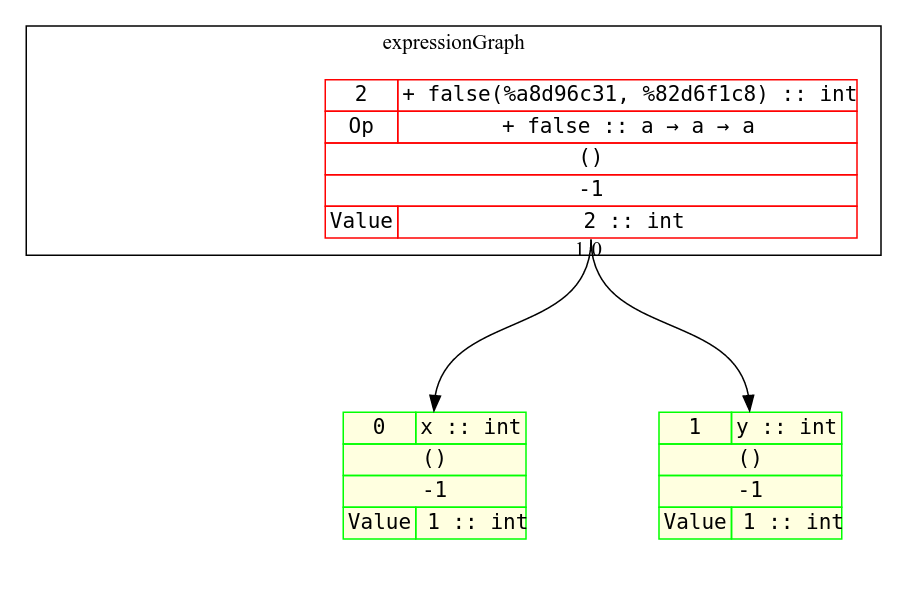
Граф нашего уравнения будет выглядеть так:
Зачем использовать объекты для графов?
После прочтения всего выше описанного, модно прийти к выводу, что если все программы это графы и математические уравнения это тоже графы, то мы модем просто использовать встроенные математические выражения. Зачем нам использовать объекты, как в примере выше, если проще написать fmt.Printf("%v", 1+1)? В конце концов, это выражение тоже будет графом. Использование объектов для таких выражений слишком избыточно.
Вы совершенно правы. Для простых уравнений использование объектов для манипулирования графами не имеет смысла(ну, только если вы не из джава мира, в котором все делается только так).
Тем не менее, для больших графов и сложных уравнений использование объектов вполне оправдано. Есть минимум три причины для такого подхода. Все это направлено на максимальное сокращение человеческой ошибки.
Вычислительная устойчивость
К примеру возьмем уравнение y = log(1+x). С точки зрения языка программирования у этого уравнения будут проблемы с вычислительной точностью - при очень маленьких x ответ, скорее всего, будет не верный. Проблема в самом устройстве float64 - просто не хватает бит для работы с диапазонами от 1 до 1 + 10e-16. Для корректной работы с уравнением y=log(1+x) необходимо использовать встроенную библиотечную функцию math.Log1p как показано в примере ниже:
func main() {
fmt.Printf("%v\n", math.Log(1.0+10e-16))
fmt.Printf("%v\n", math.Log1p(10e-16))
}
1.110223024625156e-15 // wrong
9.999999999999995e-16 // correct
Конечно, когда программист осведомлен о этой проблеме, он будет использовать math.Log1p для реализации нейронных сетей й все будет хорошо. Но, думаю вы согласитесь со мной, было бы намного лучше, если бы при работы с уравнениями вида log(1+x) автоматически использовался math.Log1p(x). Это может помочь избавится от целого ряда человеческих ошибок.
Оптимизации спицифические для машинного обучения
Рассмотрим еще один вариант программы, похожей на ту с которой мы начали:
func a() int {
return 1 + 1
}
Эта программа компилируется в ассемблер ниже:
"".a t=1 size=10 args=0x8 locals=0x0
(main.go:5) TEXT "".a(SB), $0-8
(main.go:5) FUNCDATA $0, gclocals·2a5305abe05176240e61b8620e19a815(SB)
(main.go:5) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
(main.go:6) MOVQ $2, "".~r0+8(FP)
(main.go:6) RET
В частности, обратите внимание на последний день: MOVQ $2, "".~r0+8(FP). Видно, что функция оптимизирована и сразу возвращается 2. Нет никакой операции сложения. Компилятор понимает как оптимизировать код, во время компиляции вычисляя что 1 + 1 = 2. Просто заменяя выражения константами, компилятор умудряется использовать меньше циклов процессора в рантайме. Если вам интересно побольше узнать о том как работает оптимизация в компиляторе, то почитайте о свертке констант.
Теперь мы знаем, что компиляторы достаточно умные, чтобы выполнять определенную оптимизацию кода. Но Go компилятор(как и большинство языков, не специализированных для машинного обучения) не достаточно умны для оптимизации кода специфического для машинного обучения. В большинстве случаев нам приходится использовать структуры, основанные на массивах, такие как слайсы float64, или матрицы из значений float32.
Представим, что вы вместо сложения 1 + 1 хотите выполнить []int{1, 1, 1} + []int{1,1,1}. Компилятор не сможет оптимизировать это выражение и заменить его на []int{2, 2, 2}. И вот тут использование объектов для работы с графами может показать себя во всей красе. При работе с объектами у вас появляется возможность выполнять аналогичные оптимизации. В библиотеке Gorgonia сейчас нет встраивания констант(была попытка реализовать это в более ранних версиях, но пока нет понимания как это делать правильно), но она предоставляет целый ряд других оптимизаций, например удаление общих подвыражений, когда некоторые переменные исключаются и дерево ужимается до своего минимального вида. Другие, более классические библиотеки, такие как TensorFlow или Theano, используют большое количество самых различных алгоритмов оптимизаций для работы с графами и не только.
Конечно, можно возразить, что все это можно сделать самому и написать код реализующий все эти оптимизации. Тут вопрос только в том, чем вы хотите заниматься. Я предпочитаю, больше времени тратить на само глубинное изучение, чем на различные велосипеды.
Обратное распространение ошибки
Последнее и самое важное преимущество использования объектов для работы с графами - это реализация обратного распространения ошибки. В следующих постах ч подробнее расскажу о том как реализовать логику обратного распространения ошибки и как это может помочь при вычислении частных производных. Тут вся мощь использования объектов выйдет на первый план.
Также, в следующих статьях я больше расскажу о использовании объектов для работы с графами, которые помогут нам генерировать более качественный код.
Почему Go?
Если вы работаете с гомоиконичными языками, такими как lisp или Julia, то у вас нет необходимости создавать дополнительные объекты для работы графами. Если у вас есть доступ к внутренним структурам самой программы и возможность изменять программу во время выполнения, то большинство необходимых операций модно реализовать “на лету”(если извернуться, то подобного можно добиться в Go, но это не самый оптимальный подход). Это позволяет упростить реализацию алгоритма обратного распространения ошибки переложив часть логики на рантайм. К сожалению, в случае с машинным обучением, нам придется самим реализовывать большинство структур и организовывать работ с ними.
Замечу, что это не камень в огород Go, Pyhton или Lua. Все эти языки имеют как преимущества, так и недостатки. Но почему, как по мне, Go более предпочтителен для глубинного обучения, несмотря на большое количество библиотек для того же Python или Lua? Одна из основных причин, которая подтолкнула меня на создание Gorgonia, была возможность собирать все в один банарник. Сделать такое на Python или Lua весьма нетривиальная задача. Деплоить go-прораммы одно удовольствие
Я уверен, что использование Go для работы с данными - это замечательная идея. Этот язык строго(достаточно строго для меня) типизирован, и он компилируется в один бинарный файл. Go предоставляет лучшую “механическую” связанность между различными частями системы, что позволить реализовать более быстрый и качественный AI. И не стоит забывать, что так или иначе, все наши программы запускаются на определенном железе. И я просто хочу работать с высокоуровневыми структурами для реализации своих идей. Именно это было движущей силой для меня. Надеюсь, моя реализация вам понравится и вы будете ее использовать.